




Autor: Carlos Jaureguizar
Tradicionalmente, la teoría de carteras ha utilizado un estimador simple de la matriz de correlación, una matriz fácil de calcular y que resulta muy útil si los datos cumplen con propiedades deseables tales como normalidad e independencia entre otras, sin embargo, los datos financieros son especialmente complejos porque no cumplen con esas propiedades.
De hecho, las dificultades que presenta la matriz de covarianzas en el ámbito del análisis de carteras se deben a diferentes razones entre las que se encuentran: las condiciones del mercado cambian con el tiempo y la relación entre cualquier par de activos puede no ser estacionaria; las series disponibles no son infinitas, lo que introduce el llamado «ruido de medición». Además, aunque el uso de series más largas permite mejorar el problema de la longitud finita, las estimaciones de matriz se ven afectadas por la no estacionariedad de las relaciones cruzadas, lo que hace que la matriz posea componentes aleatorias. Por estas razones, la matriz de correlación muestral no es un buen estimador para aplicaciones prácticas [1]-[3].
En este contexto, uno de los principales desafíos en el análisis financiero moderno es eliminar el ruido de la matriz de covarianzas muestral. Algunos estimadores recientes de matrices de covarianza utilizan resultados asintóticos de la Teoría de Matrices Aleatorias (RMT) [4], mientras que otros enfoques comprenden métodos de valor propio [5]–[7] cuya idea subyacente es limpiar la matriz de correlación muestral filtrando valores propios. En este sentido el teorema de Marchenko-Pastur establece que, si los elementos de una matriz son aleatorios, sus autovalores seguirán una distribución concreta (denominada Marchenko-Pastur), de modo que aquellos valores que se desvíen de dicha distribución contendrán información de la parte no aleatoria de la señal. Los autovalores, por tanto, servirán no solo para limpiar de ruido la matriz de correlaciones, sino que se podrían utilizar para generar una nueva señal de la que extraer información relevante.
Otra reciente aportación que se basa en la RMT el estudio de matrices de covarianza en el contexto del análisis de datos es la utilización de la misma dentro en los nuevos algoritmos de “deep learning”. Según [8] se puede estimar el error en una Red Neuronal “Deep” (DNN) a partir de los autovalores de la correlación de los pesos de las capas de matrices ponderadas. Si se representa el histograma de los mismos para cada capa, se puede monitorizar el proceso de aprendizaje y mejora la información sobre las propiedades de regularización y convergencia de la red.
2. Distribución Marchenko-Pastur y autovalores de matrices aleatorias
En el ámbito de los mercados financieros, los estudios de matrices de correlaciones se han centrado fundamentalmente en la correlación de los retornos del mercado de acciones. Plerou et at [9] observaron que la distribución de los autovalores de las matrices de correlación correspondía a lo que podría considerarse ruido, o pura aleatoriedad, pero con ciertas excepciones en los autovalores más altos.
El teorema de Marchenko-Pastur [10] puede utilizarse para separar los elementos aleatorios de la matriz de correlaciones de los que contienen señal y son, por tanto, relevantes. Dado que una matriz de valores aleatorios presenta autovalores en línea con la distribución propuesta por Marchenko-Pastur, se puede comparar dicha distribución con la densidad real observada. De este modo, puede conocerse en primer lugar el número de factores relevantes, simplemente contando el número de autovalores fuera del rango aleatorio. Además, esto permite utilizar técnicas de filtrado de dichos autovalores para eliminar o reducir el ruido de la correlación sin afectar a la señal.
Con el objetivo de ilustrar el procedimiento el primer paso es crear una matriz completamente aleatoria, por ejemplo, con una dimensión de 20.000 filas y 2.000 columnas.
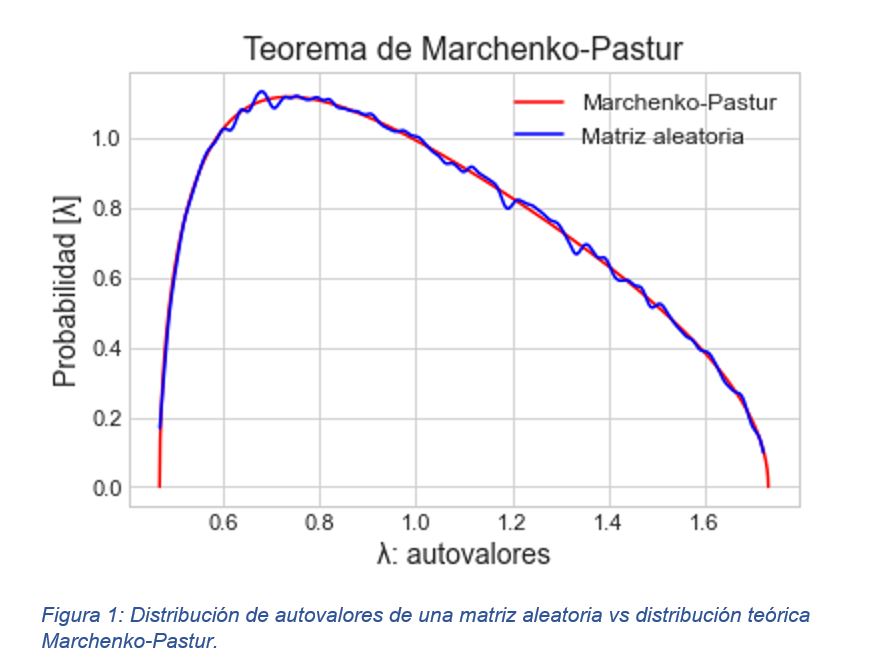
La distribución de los autovalores obtenidos de dicha matriz, junto con la distribución de Marchenko-Pastur aparecen representada en la figura 1, en la que la línea roja muestra la densidad de la distribución de los autovalores según Marchenko-Pastur, mientras que la línea azul muestra los autovalores de la matriz aleatoria que hemos creado, ajustándose con claridad a lo esperado.
Suponiendo que los autovalores de una matriz de correlación de los retornos de los componentes de una cartera se distribuyen del mismo modo que en la figura 1 se podría concluir el comportamiento de dicha matriz corresponde a datos puramente aleatorios. Sin embargo, lo que se observa en la práctica es que una parte importante de los autovalores se ajustan al rango de Marchenko-Pastur, pero otros se encuentran fuera de dicho rango, por lo que puede suponerse que la matriz presenta tanto ruido como señal.
Antes de verlo en la práctica, veamos qué ocurre si a una matriz completamente aleatoria, como la anterior (20.000×2000) le añadimos una parte de señal (no ruido aleatorio). Para ello, seguimos a López de Prado [11] y añadimos 200 factores que incorporen señal, es decir, 200 autovalores fuera del rango Marchenko-Pastur.
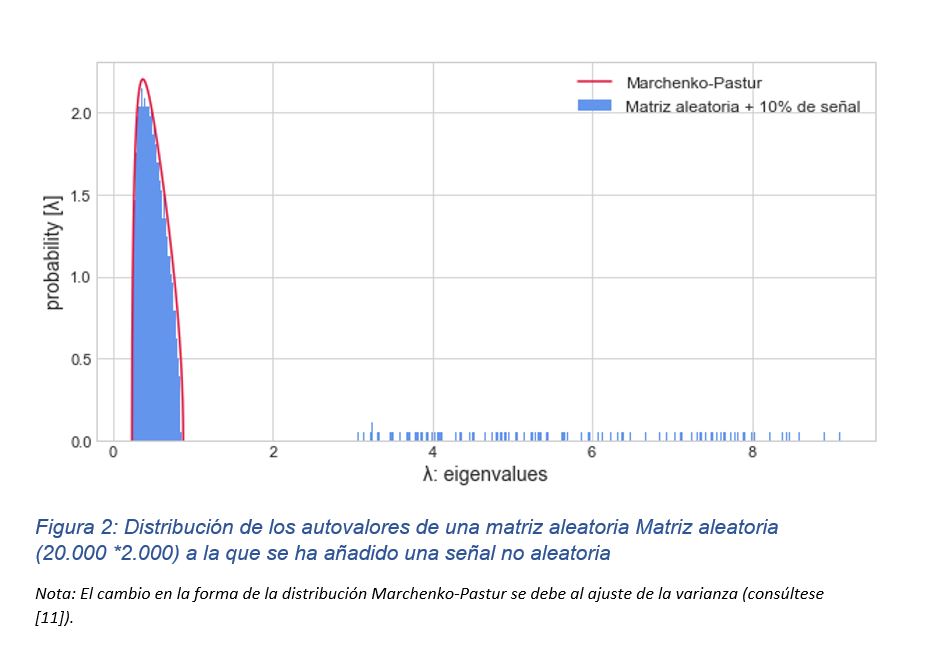
Tal y como muestra la figura 2. algunos autovalores corresponden con un comportamiento aleatorio (bajo la línea roja) pero otros se corresponden con uno no aleatorio. Esto permitiría separar la parte aleatoria de aquella que contiene la información relevante.
En la figura 3, se muestran los mismos autovalores en una gráfica en la que simplemente se ordenan los 800 autovalores de menor a mayor. Este gráfico resulta especialmente útil para entender técnicas de filtrado, ya que la primera parte de los autovalores es la que corresponde al ruido de la señal, por lo que el objetivo es encontrar la forma de eliminar dichos autovalores. El procedimiento para hacerlo es lo que se denomina “filtrado” o “denoising”.
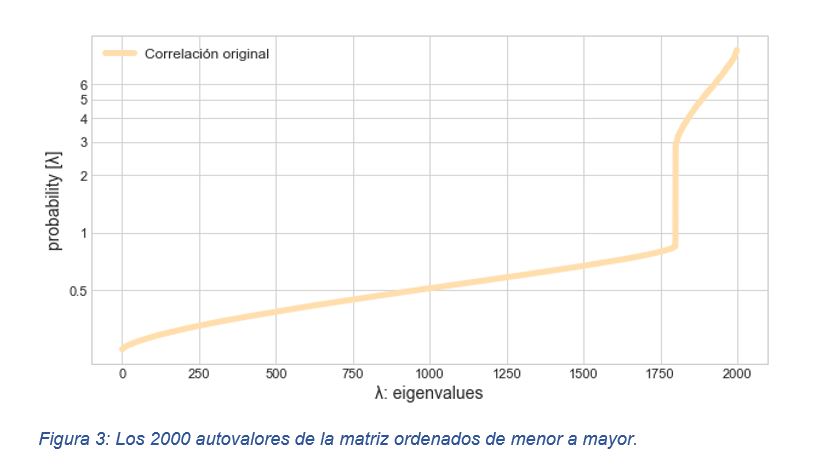
Así, la primera parte, hasta que se produce un salto, corresponde a autovalores dentro del rango Marchenko-Pastur, mientras que, la parte que se encuentra a la derecha de línea discontinua corresponde a autovalores fuera de dicho rango.
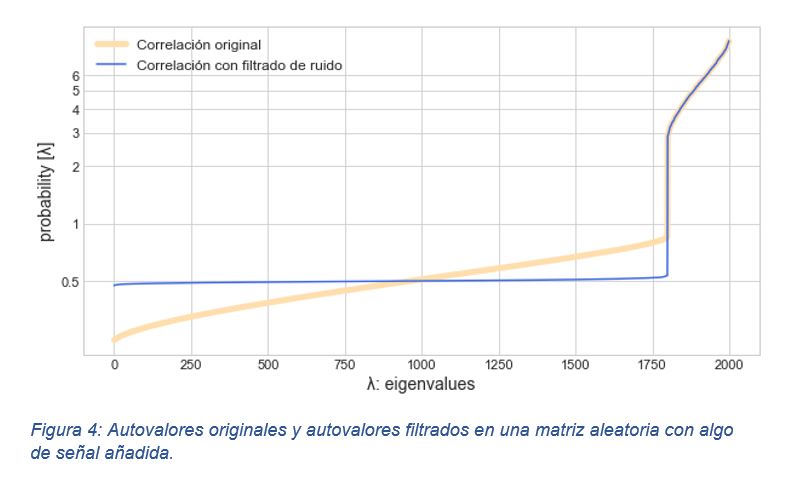
Para mejorar el ajuste, siguiendo la propuesta de López de Prado [11], se realiza un cambio en la varianza que se fija en 0,508 en lugar de 1, por lo que cualquier autovalor que esté por encima de λ+, en este caso 0,88, podrá considerarse no aleatorio y por tanto contendrá señal, no ruido.
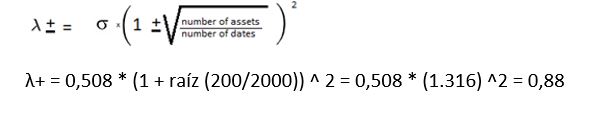
3. Procedimiento de filtrado de ruido.
Existen distintas maneras de filtrar el ruido de las matrices de correlación, dentro de las cuales cabría citar, siguiendo a [9]:
1. Contracción lineal básica.
2. Contracción lineal avanzada.
3. Recorte de autovalores (Bouchaud y Potters 2011 [12]).
4. Sustitución de autovalores.
5. Contracción óptima rotacionalmente invariante.
En el caso que se expone a continuación, se sigue a Bouchaud & Potters [14], donde se establece que puede filtrarse el ruido de una matriz si se mantienen los autovalores más elevados, los que está por encima del umbral de Marchenko-Pastur (λ+) y se comprimen los demás en uno constante.
4. Caso práctico: Footsie 100
Para ilustrar el procedimiento se utilizarán los precios de cierre diarios de los componentes del índice Footsie 100 durante aproximadamente tres años y medio, desde el 10 de mayo de 2018 hasta el 25 de octubre de 2021. Dichos datos han sido limpiados, eliminando fechas con datos insuficientes y generando los retornos logarítmicos en forma de matriz de dimensión 1342 x 100 (1342 fechas y 100 acciones).
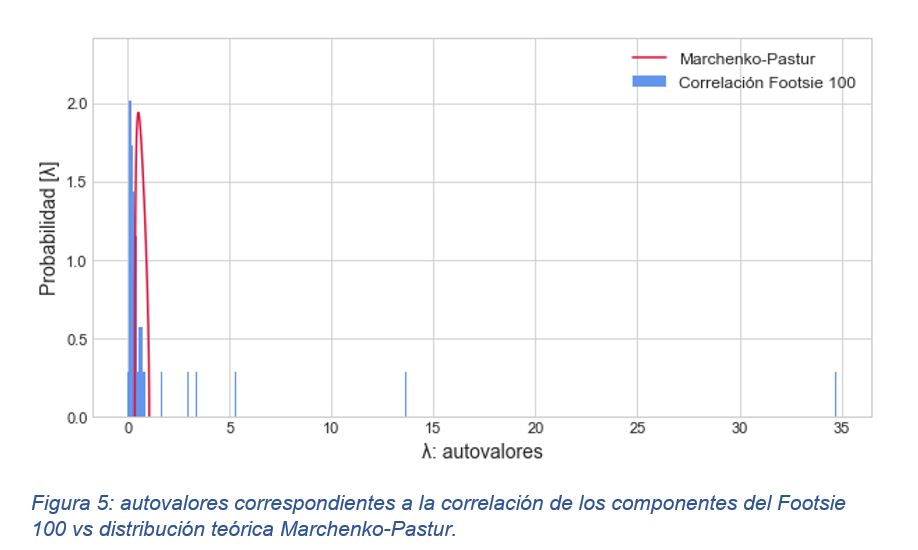
Tal y como se explicó en el epígrafe 2, la línea roja muestra la distribución teórica de los autovalores de una matriz de 1342 x 100 según [10] mientras que las líneas azules muestran la distribución empírica de la matriz de correlación de los componentes del Footsie.
Dado que los límites del rango de los autovalores vienen dados por la siguiente fórmula:
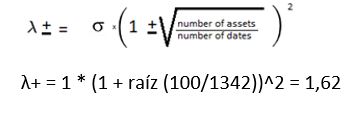
en el caso que se está tratando, por encima de 1,62 solo se presentan seis autovalores, concretamente: [34,73] [13,62] [ 5,27] [3,30] [2,93] [1,81]mientras que 94 autovalores corresponderían a ruido aleatorio.
En este punto, hay que sustituir 94 autovalores que contienen ruido por uno constante, que puede ser la media de todos ellos. Una vez hecho, se reconstruye la matriz de matriz de covarianzas y su correspondiente matriz de correlaciones para obtener una filtrada (siguiendo a [11]).
Siendo:
avec: Matriz de vectores propios.
naval: Matriz con los nuevos valores propios filtrados.
avec’: Matriz traspuesta de los vectores propios.
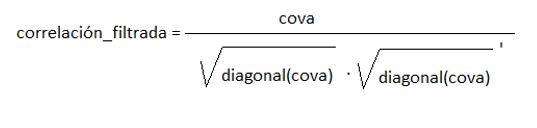
cova = avec .* naval .* avec’
En la figura 6 puede observarse gráficamente el resultado después del filtrado
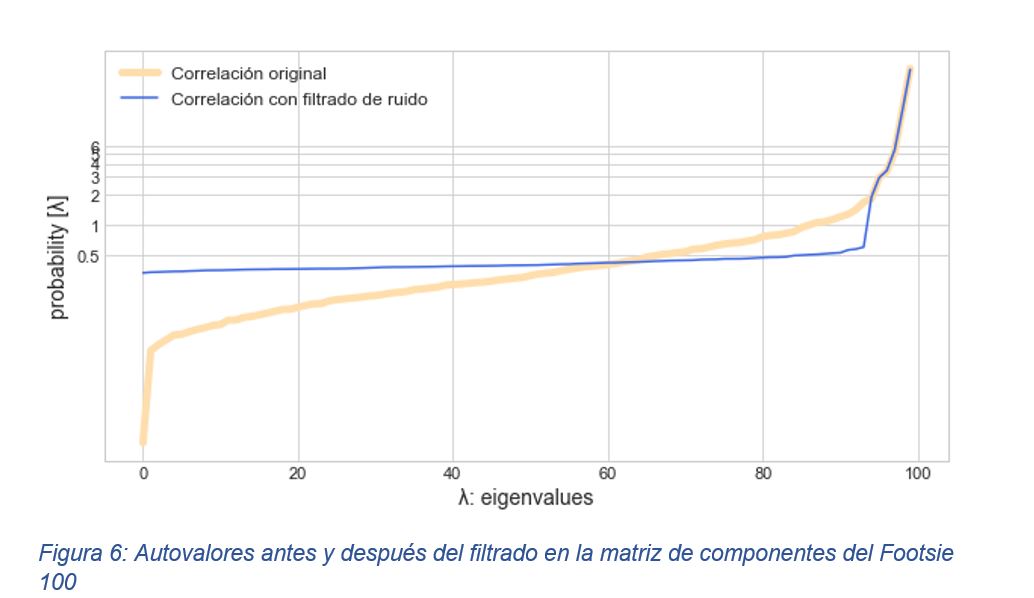
Como es lógico, existen diversas objeciones al método de filtrado de las matrices de correlaciones, entre las que destacan las que afirman que dichas técnicas se sobreestiman los autovalores más elevados [15] o aquellas que indican que asumir puro ruido en la zona gruesa (bulk) es demasiado estricto, sin embargo, los resultados que pueden obtenerse mediante dichas técnicas mejoran los resultados que pueden obtenerse al utilizar las matrices de covarianzas de retornos de los activos en el análisis de carteras y riegos de los activos
5. Conclusiones.
Las matrices de correlaciones entre activos se utilizan muy a menudo por parte de los analistas e inversores cuando se estudia la relación entre la evolución de los rendimientos de los activos. Sin embargo, la comparación con la distribución teórica de los autovalores de una matriz aleatoria según Marchenko-Pastur, con los obtenidos de la matriz de correlaciones de los activos muestra que la relación entre ruido y señal cuando se estudian los datos de rendimientos en mercados financieros es muy alta, por lo que la presencia de ruido es muy superior a la de señal. Sin embargo, partiendo precisamente del teorema de Marchenko-Pastur pueden emplearse técnicas de filtrado que reducen el ruido, mejorando la utilidad de las matrices de correlación.
Referencias bibiliográficas
[1] Y. Feng and D. P. Palomar, “Portfolio optimization with asset selection and risk parity control,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2016, pp. 6585–6589.[2] Bun, J., Bouchaud, J. P., & Potters, M. (2017). Cleaning large correlation matrices: tools from random matrix theory. Physics Reports, 666, 1-109.
[3] L. Yang, R. Couillet, and M. R. McKay, “A robust statistics approach to minimum variance portfolio optimization,” IEEE Trans. Signal Process., vol. 63, no. 24, pp. 6684–6697, Dec. 2015.
[4] Ledoit, O., & Wolf, M. (2017). Nonlinear shrinkage of the covariance matrix for portfolio selection: Markowitz meets Goldilocks. The Review of Financial Studies, 30(12), 4349-4388.
[5] L. Laloux, P. Cizeau, J.-P. Bouchaud, and M. Potters, “Noise dressing of financial correlation matrices,” Phys. Rev. Lett., vol. 83, no. 7, p. 1467, Aug. 1999.
[6] L. Laloux, P. Cizeau, M. Potters, and J.-P. Bouchaud, “Random matrix theory and financial correlations,” Int. J. Theoret. Appl. Finance, vol. 3, no. 3, pp. 391–397, Jul. 2000.
[7] V. Plerou, P. Gopikrishnan, B. Rosenow, L. A. N. Amaral, T. Guhr, and H. E. Stanley, “Random matrix approach to cross correlations in financial data,” Phys. Rev., vol. 65, no. 6, p. 066126, Jun. 2002.
[8] Martin, C.H., Peng, T y Mahoney, M.W. Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data. Nat Commun 12, 4122 (2021).
[9] V. Plerou, P. Gopikrishnan, B. Rosenow, L. N. Amaral, and H. E. Stanley. Universal and non-universal properties of cross-correlations in financial time series. Physical Review Letters, 83:1471{1474, (1999).[10] V. A. Marchenko and L. A. Pastur. Distribution of eigenvalues for some sets of random matrices. Matt. USSR-Sbornik, 1:457486, (1967).[11] López de Prado, M. Machine Learning for Asset Managers (Elements in Quantitative Finance). Cambridge: Cambridge University Press, (2020). doi:10.1017/9781108883658[12] Scott Rome. “Eigen-vesting III. Random Matrix Filtering in Finance“. Online: March 30, 2016. https://srome.github.io/Eigenvesting-III-Random-Matrix-Filtering-In-Finance/[13] Silverman, B. W., and M. C. Jones. “E. Fix and J.L. Hodges (1951): An Important Contribution to Nonparametric Discriminant Analysis and Density Estimation: Commentary on Fix and Hodges (1951).” International Statistical Review / Revue Internationale De Statistique, vol. 57, no. 3, 1989, pp. 233–238.[14] Potters, Marc & Bouchaud, Jean-Philippe. “The Oxford Handbook of Random Matrix Theory: Chapter 40 Financial Applications”, (2011).
[15] Joël Bun, Marc Potters, Adam Rej: “Cleaning correlation matrices”. Risk Magazine’s (April 2016 issue).[16] Yeo, Joongyeub & Papanicolaou, George. “Random matrix approach to estimation of high-dimensional factor models”, (2016).
Autores:
Carlos Jaureguizar. Actualmente, CEO de Robexia AI TechConsulting, un laboratorio de Inteligencia Artificial especializado en el sector financiero y asegurador. Previamente, trabajó en la Tesorería de BBVA y ha ocupado cargos en la junta de IFTA y como presidente de IEATEC. Actualmente participa en el Comité para la transición a Inteligencia Artificial de IEATEC.
Académicamente, Carlos Jaureguízar es Licenciado en Economía (UAM), Máster en Mercados Financieros (UAM) y posee la certificación ACI FX y MM Nivel I. Adicionalmente, aprobó el examen DEA con una disertación de modelo de optimización inversa Black-Litterman y obtuvo un doctorado en Economía Aplicada, con mención cum laude, tras la defensa de la tesis: “¿En qué medida los patrones de velas anticipan la continuación o el giro de la tendencia de los precios cotizados?”.
En cuanto a publicaciones, además de ser autor de numerosos artículos y participar activamente en foros y conferencias, Carlos Jaureguízar es autor de dos libros de Negociación “Alta rentabilidad en la bolsa y otros mercados financieros” y “Candlestick para traders”.
Como emprendedor, además de fundador de Noesis, Robexia y Finavid, Carlos Jaureguízar es socio fundador de Contacto, una agencia de publicidad y socio fundador de Aquinas American School.
Pilar Grau Carles es Catedrática de Economía Aplicada de la Universidad Rey Juan Carlos. Sus intereses de investigación abarcan tanto las finanzas computacionales como el estudio de redes. En el área de finanzas ha explorado las propiedades de las series temporales financieras. En la ciencia de redes se ha centrado en el análisis de redes sociales, financieras y de datos. Su investigación ha sido publicada en revistas académicas como Computational Finance, Journal of Business Research, Applied Economics o International Review of Economics & Finance.